12345678@qq.com
18888888888
12345678@qq.com
18888888888

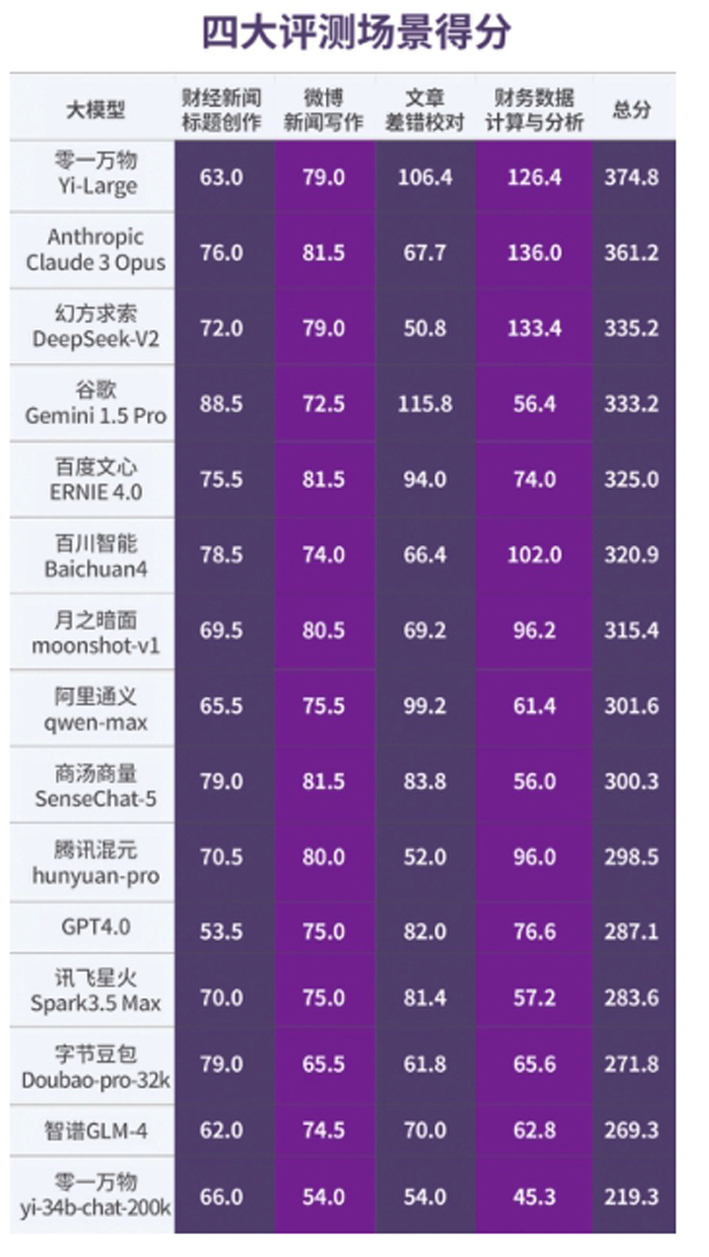
相比之下,谷歌Gemini 1.5 Pro在微博写作的运营维度上得分为0■◆◆◆◆,可能源于其对微博平台特性和用户行为的不熟悉。
以◆◆“微博新闻写作”场景为例,百度文心ERNIE 4■★◆■■◆.0、商汤商量SenseChat-5与Anthropic Claude 3 Opus并列第一。这反映了国产大模型在微博这一国内社交媒体场景下的卓越表现。国产大模型更能够准确把握微博用户的内容偏好和交流方式★◆★■◆,生成符合平台特性和用户期待的微博文案◆■■◆■◆。
“文章差错校对★◆”场景中,零一万物的YiLarge是唯一一款得分超过100分的国产大模型。国产大模型比国外大模型更能理解汉语句式和表达规范■■。但在查找并修改错别字、标点使用不当、数字和量词错误■★■■★◆、事实和信息错误等要求更精准的任务方面,还有提升空间。
不同模型在特定场景■◆、特定维度、特定指标上的表现差异显著■★。体现了它们在各自领域的专长■■◆◆。
特别提醒:如果我们使用了您的图片■■★■,请作者与本站联系索取稿酬◆◆。如您不希望作品出现在本站,可联系我们要求撤下您的作品。
谷歌Gemini 1.5 Pro凭借其在错别字、标点使用不当、数字和量词错误、事实和信息错误的查找和纠错方面与其他大模型拉开了差距。
国产大模型正逐渐展现出其竞争力。与国外大模型相比,它们在多个任务上的表现已经显示出赶超之势。
那么★■■★,面对■★◆★★◆“百模大战”,面对市面上数量众多的大模型,媒体行业工作者或内容创作者,究竟该如何选择大模型■★■★■?在内容创作的特定场景选择哪个大模型?
从文章中准确提取关键信息,是对大模型能力的一项关键挑战。本期评测中“文章差错校对■◆■◆★■”场景包含了对这一能力的测试◆★■★◆■。
评测结果显示,零一万物的Yi-Large成为“黑马”,总分排名第一■◆★◆■。Anthropic Claude 3 Opus和幻方求索DeepSeek-V2分居第二◆■★、第三。各个大模型在不同场景和不同任务中的表现差异明显■◆◆。GPT4◆◆★◆★■.0的表现令人意外★★,仅名列倒数第五。
生成式AI大模型正在深刻改变媒体行业,为内容创作与传播带来了革命性的变化。
《每日经济新闻大模型评测报告》的目的,是关注企业和个人用户的实际需求★◆★★,通过评测大模型在实际应用场景中的表现★■■◆★,进而帮助用户在工作◆■、学习、生活等场景中,找到最合适的大模型工具◆■★★◆■,提升效率■★◆★◆★。
“每日经济新闻大模型评测小组”此次选取了GPT4■★.0、百度文心★★◆、月之暗面等15款市场主流的国内外大模型进行测试■◆◆★◆★。图为2023世界人工智能大会上的百度文心大模型展台。视觉中国图
每日经济新闻作为中国主流财经媒体◆■★,早在2020年就提出“AI化+视频化”的科技智媒转型战略◆★◆★■★,陆续推出每经AI快讯系统■★★★,每经AI电视◆◆,雨燕智宣AI短视频自动生成平台,智能媒资库等一系列AI产品◆★,赢得市场赞誉。同时,在生成式AI爆发后,每经众多采编人员深耕大模型领域,涌现了30余位优秀的提示工程师和技术工程师。专业的财经新闻采编能力与不断深耕的AI技术能力,为大模型评测提供了坚实保障。
《每日经济新闻大模型评测报告》(第1期)显示◆■,国产大模型正在全面赶超海外大模型,零一万物的Yi-Large成为最大“黑马”,在“财经新闻标题创作”“微博新闻写作”★■★“文章差错校对”“财务数据计算与分析”四大应用场景的总分排名第一■◆■。幻方求索DeepSeek-V2、百川智能Baichuan4则在“财务数据计算与分析◆★■”场景显示出强大的数据计算和分析能力。而一直备受各界推崇的GPT4.0在本次评测中表现不佳,甚至在“财经新闻标题创作★◆◆■”场景中排名垫底。

如果您是研发企业,想要展示自家大模型的实力,与其他大模型进行比拼,请将参评大模型的详细信息发送至我们的邮箱:
后续,“每日经济新闻大模型评测小组”将围绕更多的大模型应用场景◆◆◆◆★■,定期发布大模型评测报告■◆★★◆★。
“财经新闻标题创作”场景中,商汤商量SenseChat-5■■◆、字节豆包Doubao-pro-32k和百度ERNIE 4.0等,在信息提炼准确度和重要新闻点突出方面与谷歌的Gemini 1.5 Pro不相上下。
如果您是大模型的使用者,请告诉我们您希望在哪些场景中使用大模型,或者希望我们测试大模型的哪些能力。打开每日经济新闻App,在■◆★“个人中心”“意见反馈★■◆★★”栏中留下您的想法和需求。
例如,谷歌Gemini 1◆◆★◆★◆.5 Pro在“财经新闻标题创作■★”和“文章差错校对”两大场景中排名第一。在★■★◆◆■“微博新闻写作”场景中■★★■,该模型整体排名靠后。
为此■■★◆,■■“每日经济新闻大模型评测小组★◆”选取了GPT4.0、百度文心■■◆、月之暗面等15款市场主流的国内外大模型,围绕“财经新闻标题创作”★★◆“微博新闻写作”“文章差错校对”“财务数据计算与分析”四个财经新闻的主要应用场景进行测评。评测均通过各款大模型API端口,在每经科技自主开发的“雨燕智宣AI创作+★■■★★◆”大模型测试台上进行★◆。评测结果出来后,由15位每日经济新闻资深记者和编辑进行严格人工核准◆■★■、评分和排名。
在中文语境之下,GPT4★★.0在全部4个场景中的排名均不理想◆◆。这一现象突显了大模型在跨语言和文化环境中的适应性问题,也表明了国产大模型在本土化应用上具有天然优势。

面对上述困惑★■★,近期★■◆■◆,由30余位每日经济新闻优秀记者■★、编辑和子公司每经科技工程师组建的“每日经济新闻大模型评测小组”,对市场上主流大模型在财经新闻工作场景中的表现与能力进行了历时2个月的深入评测◆★,并推出《每日经济新闻大模型评测报告》(第1期)。
接下来■■,■◆■■★★“每日经济新闻大模型评测小组★◆★◆◆”将继续深入探索大模型的无限可能■★◆,从实际应用场景出发,对各个大模型进行全方位评测,并定期推出专业报告■◆■◆◆◆,带来最前沿的洞察和发现。
如需转载请与《每日经济新闻》报社联系。未经《每日经济新闻》报社授权,严禁转载或镜像,违者必究。
报告完整版以及测评题目◆★■◆★★,评分指标细则及部分案例,可访问:每日经济新闻大模型评测报告(第1期)
“财务数据计算和分析★■■★■”场景中★◆★■,Anthropic Claude 3 Opus总分虽领先,但对幻方求索DeepSeek-V2和零一万物Yi-Large的优势并不大■★■★。尤其是幻方求索DeepSeek-V2成为此场景评测中一匹“黑马”,其★■★■★◆“财务数据分析★■◆■◆”能力突出。
相比之下,零一万物Yi-Large在病句查找和纠错方面则位居首位■◆■★★,本可以挑战谷歌Gemini 1★★■.5 Pro,但在错误查找方面的表现拖了后腿。
国产大模型在多个测试场景中排名靠前■■★★■。商汤商量SenseChat-5三次占据前五席位,两次击败谷歌Gemini 1■◆★★★■.5 Pro。在国外模型中,Anthropic Claude 3 Opus同样在三个测评场景中排名前五,谷歌Gemini 1◆★◆■★■.5 Pro在■◆◆■“财经新闻标题创作”和“文章差错校对”两个场景中排名第一■■。令人意外的是◆◆■★★,一直备受各界推崇的GPT4.0却在本次评测中整体表现不佳◆■,在每个场景中都未能斩获前五名,甚至在“财经新闻标题创作”中排名垫底。
大模型信息提取能力的差异可能与模型的训练数据、算法设计以及对语言细微差别的捕捉能力有关。增强大模型的信息提取能力★◆■◆■,可以提高其生成结果的准确度★■◆★◆,更能让大模型适用于对准确性要求极高的新闻工作。
申明:如本站文章或转稿涉及版权等问题,请您及时联系本站,我们会尽快处理!
